
開発時期:2022年
開発者:AmpiTa Project
開発言語:C#言語(Visual Studio 2022)
背景・概要
病院や診療所、薬局などの医療機関の情報は、1軒ずつ調べるのであればネット検索で用が足りるかもしれませんが、営業戦略を立てるといった場合には一覧表が欲しくなります。
信頼できる最新情報はどこにあるか調べたところ、厚生労働省でした。
しなしながら、そのデータは扱いづらいものでした。
そこで、厚生労働省のデータをまとめるシステムを開発しました。
厚生労働省提供
厚生労働省から無料で提供してもらえるExcelファイルは、開くと下図のようなシートが出てきます。
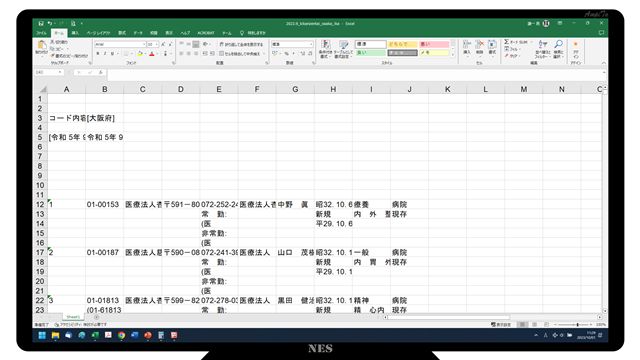
冒頭の11行には個別データではなく、僅かな情報が掲載されています。
B3セルに都道府県名が入っているのですが、ここが空欄の都道府県もあるのでシートだけでは都道府県名が識別不能です。
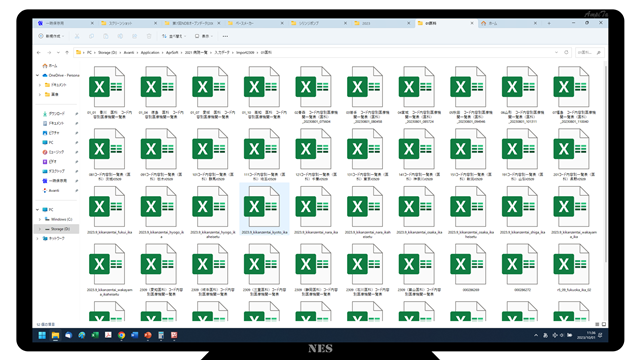
47都道府県別Excel
厚生労働省が提供するExcelファイルは47都道府県がすべて別々のファイルです。
すなわち、最低でも47個のファイルがあります。
実際には、北海道の医科が病院と診療所で別々に提供しているので48ファイルになります。
さらに、医科・歯科・薬局でも分かれるので、1つの県で3つのファイルは当たり前です。
1行1軒ではない
医療機関別のデータは下図の通りです。
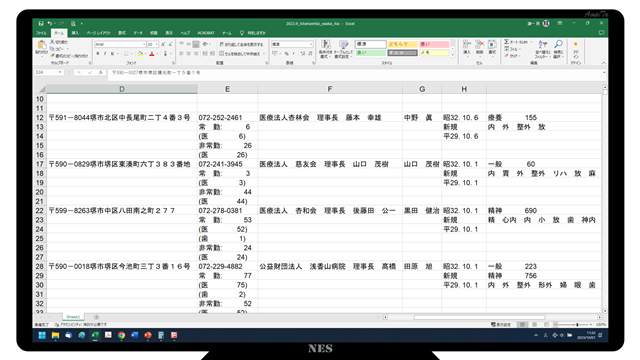
このシートではExcelの12行目に1軒目の医療機関があり、16行目までの5行で1軒となっています。
次が17~21行目までの5行で1軒です。
次が22~27行目までの6行で1軒です。
このバラバラの状態から、1軒ずつのデータにする必要があります。
基本構想
Excelファイルをダウンロードする作業は手作業としました。自動の場合、何らかのブロックがあると考えられることと、毎月同じ形で提供されるかわからないためです。
Zipファイルをダウンロードして、Excelファイルとして医科・歯科・薬局・施設届出の4つのフォルダに分けるところまでは手作業とします。
フォルダからExcelファイルを読み取り、エラーチェックをしてXMLファイルに変換するプログラムをC#で開発します。
変換時に医療機関名や所在地、病床数など現に記載のある内容を自動分類して集計することとします。
営業ツールなどで利用するため、二次医療圏を把握すると有用であると考え、所在地から二次医療圏を割り出して付記する機能も加えることにします。
集計後のデータは内部データベースとして利用しますが、一部はウェブサイト上で公開しようと考えているため、部分的に抜き出してCSVファイルを作る機能も加えます。
基本設計
XMLファイルの項目名を決定します。今回は項目数が多く、しかもデータ数(件数)も多いため、慎重に設計します。
流れに乗せる
Excelファイルの読み込みは外部との関係がありますが、それ以降は内部処理に近くなります。
そのため、後の処理をワンクリックで終わらせるのか、小分けにするのかは開発者の裁量です。
実際にプログラミングしてみて、複雑だなと思ったもの、処理に時間がかかるなというものは分けました。
結果として、手順が1~6に分かれました。
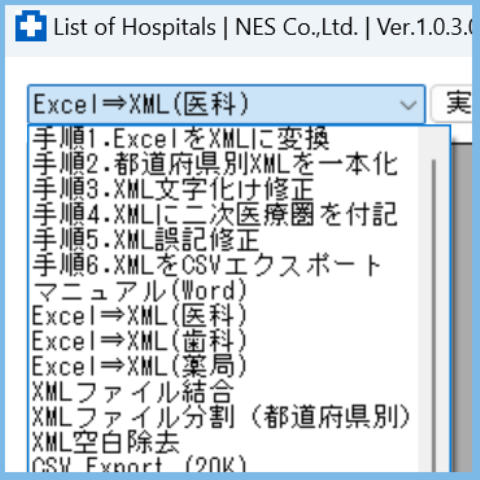
Excel読込
手順の最初は、厚生労働省提供のExcelファイルを読込みます。
まずは手作業でフォルダ毎に医科、歯科、薬局を分けて保存します。
ダイアログでフォルダを指定し、そのフォルダ内にあるExcelファイルをすべて読込みます。
事前処理として、Excelファイルを一度開いてB3セルに都道府県名が入力されているか確認します。
B3セルが空欄などエラーが出た場合、そのファイルを既定のプログラムで開きます。
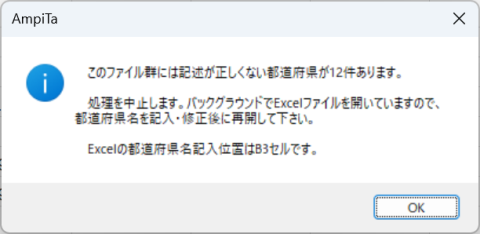
実際に処理すると関東のExcelファイルは軒並み都道府県名が空欄なので、エラーとなって毎月下図のような画面になります。
Excel ⇒ XML
Excelファイルの読み込みが確定すると、1ファイルずつ、1行ずつ読込みます。
そのデータは、都道府県毎のXMLファイルに変換されます。
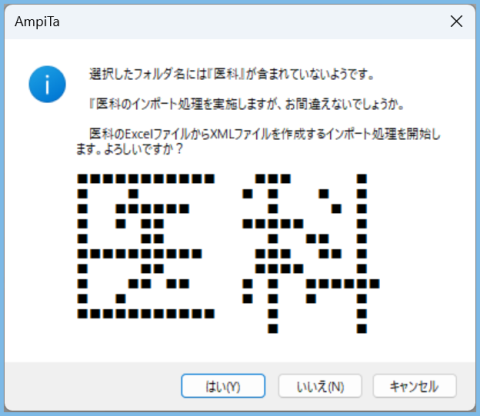
実行後、下図のようなメッセージが出ます。
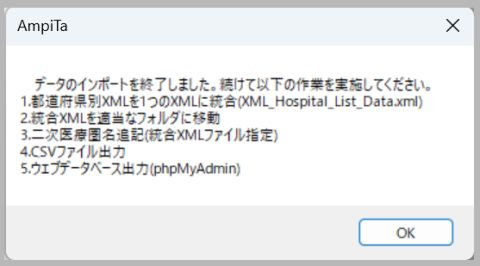
都道府県別XMLを一本化
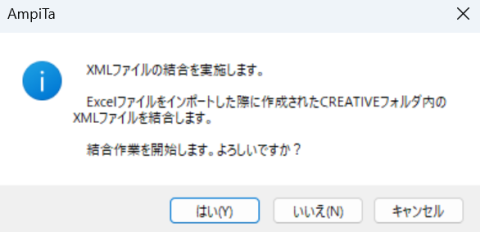
47都道府県それぞれにXMLファイルが出来上がるので、それを1つのXMLファイルにまとめます。
自動化しても良いような処理ですが、Excelファイルのインポートが失敗ありきなので、ここでワンクッションを置く事にしています。
文字化け修正
厚生労働省から受け取るExcelファイル内には、表示困難な文字が含まれていることがあります。
そこで、キャラクタコードを取得して、どのような文字を表現しようとしていたのか解析し、一般的に表示できる文字に置き換えています。
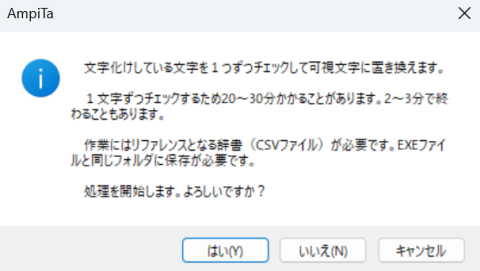
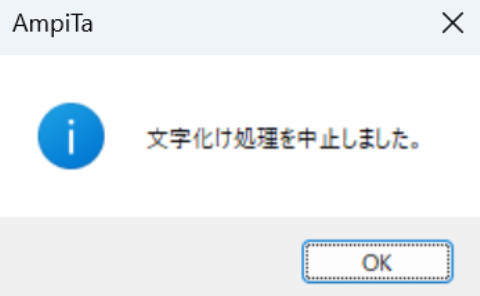
この処理は医科だけでも10万件以上ある全医療機関を1軒ずつ、そして1文字ずつ検証するため、膨大な時間がかかります。
時間やCPUに余裕がないときに処理すると困ったことになるので、中止することも想定しています。
二次医療圏
医療機関は都道府県より細かく、市町村より広域な二次医療圏が指定されています。
所在地を抽出して、二次医療圏と突合し、記録します。
この処理も10万軒以上ある医療機関を、数百ある二次医療圏との突合を行うので、相当に時間が掛かります。
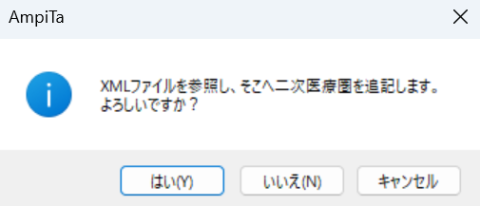
誤記修正
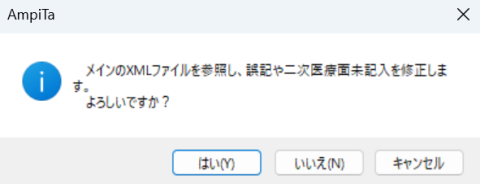
読解不能な文字については先ほど修正しましたが、文字として誤りではないが、所在地として存在しない地名であるなどの場合、それを修正するプログラムを実行します。
『鯵ヶ沢』や『鎌ヶ谷』のような『ケ』の文字が違うといったことはよくあります。
この処理を終えると、Excel・XMLファイルの処理は完了します。
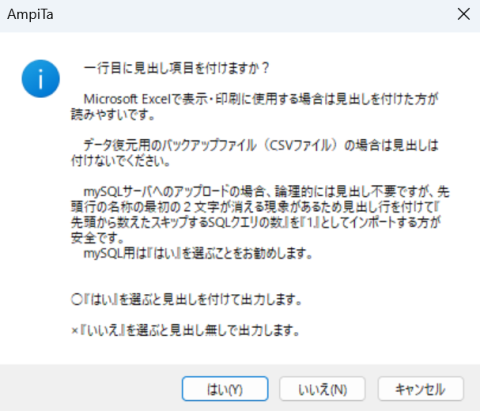
CSVエクスポート
XMLファイルをCSVファイルに変換します。
全件を1つのファイルにすることもできますが、サーバへのアップロードで制限がかかる可能性があるので、10,000件などに分割してエクスポートもできます。
おわりに
今回開発したソフトウェアは、厚生労働省が提供するExcelファイルが、集計に不向きな、印刷出力ありきで作られているようなファイルであったため、独自の集計をしたいがための自己使用ソフトウェアです。
